
We are certainly living the AI hype. With the endless stream of AI generated content that keeps people guessing – “Is this real?”. Most of the recent hype can be attributed to the Large Language Model. This is a huge Machine Learning model that has reached extraordinary performance and skill on reading and creating language.
I remember how surprised I was after using ChatGPT for the first time – I was baffled at how natural and coherent it sounded. You can ask is anything and it gives a good answer; I think that was the main lightbulb moment for me. Previously in this area, all our efforts creating AI models were very specific to a task – finding objects in an image; summarising text or translating sentences. All of a sudden we can use one model, for many tasks. This is just amazing!
Have you ever wondered how AI like ChatGPT can understand and generate humanistic text? It might seem like magic, but it’s actually a combination of clever mathematics, vast amounts of data and a huge neural network. In this post, I’ll explain all about how language models work, and even shine some light on the underpinning – popular architectures, which is often left of discussions unless you are working in AI.

If you haven’t read my previous post on the fundamental AI definitions, you might just want to revisit – particularly the neural network and machine learning sections!
AI Doesn’t Read Text As We Do, There Are No Letters, Only Numbers
Before we dive in, let’s get one thing straight—AI doesn’t “think” or “read” like humans.
When you type a sentence into an AI, it doesn’t actually “read” your words. Instead, it breaks the words into tiny pieces (called tokens), which could be words, parts of words, or even just letters.
For example, the phrase:
“The Algorithm Edit!”
Might get broken down into tokens like this:
<”The”, “Algorithm”, “Edit”> or maybe <T, h, e, A, l, g, o, r, I, t, h, m, E, d, I,t>
These tokens are converted into numbers, using a dictionary, so the model can process them mathematically. A dictionary works by finding a word, say algorithm in your dictionary and replacing it with the number that it is associated with.
This might sounds familiar, it’s a bit like the way that you would use the Caesaer ciphers in school to encode messages, where A=1, B=2, …
For example, you might end up with these tokens.
<346, 789, 1, 1890, 17893>
It’s this list of numbers that the model can actually read.

As an aside, the choice of tokeniser affects model performance. Some tokenisers support lots of languages, others only support one. Some break words into very small pieces, others into larger pieces. It’s a key part of the design process. Some common ones are SentencePiece and BPE.
Model: Lots of Multiplication and Addition
After the tokens are created, they are passed over to the main section of the model for ‘reading’.
The Model Architecture Describes How Tokens Are Read and Understood
How the model is structured is called the architecture. There are many different types of architecture that various researchers have created over the years. I won’t give you an in-depth insight into them all; we’d be here all day. Besides, many companies keep this secret – as their special sauce to how they make their model so good!
The architecture describes how numbers (e.g tokens, e.g words) are combined to make new numbers, ultimately ending with a prediction on the next token (e.g word).
Some companies; like Meta and Microsoft (very very helpfully for us researchers) have published several of their models and anyone can download and run it. You can check them out here and here.
You can have models which are better for remembering lots of the convention history, models which are smaller and faster to run, and models which scale better as your prompts get longer. The architecture choices play a huge role in these trade-offs.
Two specific architectures I will mention here are the transformer and the mixture of experts. These underpin most of the best LLMs out there today (as of 2025). And although they are not the only ones (special mention to the recurrent neural network and the Mamba architecture) they are extremely popular and it is important to know they exist.
Transformers: The Engine Behind AI Magic
Let’s start with the transformer. Popularised by the infamous paper Attention is All You Need, 2017. The transformer revolutionised language models – massively increasing their abilities and enabling models to be trained over huge datasets.
ChatGPT, Claude and DeepSeek, and pretty much all of the famous LLMs are built from the transformer. Its even in the name GPT – Generative Pretrained Transformer!
Instead of reading text one word at a time, like older models, transformers look at entire sentences and even paragraphs at once. This helps them understand context—which is why AI-generated text sounds much more natural.
The transformer model has two smaller models. The encoder and the decoder. These are both neural networks, trained with machine learning.
Within these neural networks, the transformer also leverages a mathematical function called attention (which enables more context to be stored, helping the model understand which bits are important to remember). This function is a pretty vital reason why the transformer has surpassed other architectures!

Lets go through how the encoder and decoder work.
The encoder encodes the prompt, capturing context and meaning
The encoder is where your input prompt is read and processed. In several self-attention layers (special memory encoding functions) the encoder model parameters are adapted to contain the context from the input, so when we come to predict new words – the model has an idea of which words are more likely based on what we have seen before.
The number of words (or in ML terms tokens) the model can read in a single turn is called the context length. Models with a longer context length can deal with much longer input prompts – which is great if you have large documents for it to read. GPT-4o has a context length of 128,000, which is very approximately 70,000 words (estimating 2 tokens per word).
Input prompting is super important to getting the most out of a transformer, the higher the quality the input prompts- the better the LLM response will be. This is why the role of a prompt engineer has been created, something I discuss in here.
Think of it like you are having a conversation with someone new. Bringing up a complex topic out of the blue probably will mean your conversation will struggle initially, but the longer you are chatting, the more you develop a mutual understanding, and the deeper your conversation will get.
Encoding and prompting is a bit like that.
The decoder is the smart text prediction part of the model.
Then the decoder will iteratively predict the next word in the sentence; using all of the context that the encoder has learned AND using the sentence that it has created so far.
Piece by piece the decoder takes in the sentence, uses the context and then predicts a token. It adds the token to the sentence and repeats until it decides it has finished.
The decoder is also the part responsible for the generated content and hallucinations.
Remember it is not magic, just clever combination of numbers and functions
That is the LLM, nothing magical, nothing crazy. It’s just a lot of big numbers linked together with smart functions. The fact we have been able to programatically build a model that makes connections between words and creates such natural sounding sentences is quite magical.
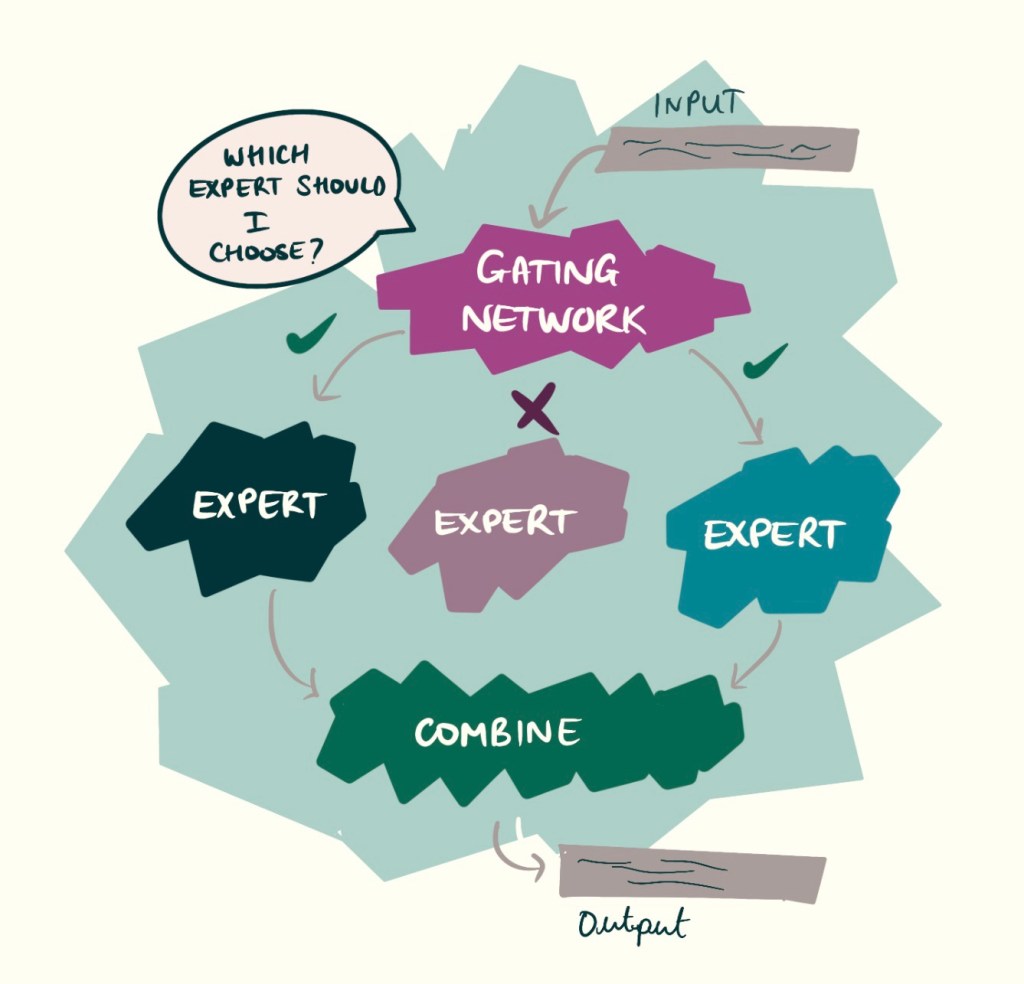
Mixture of Experts: Why have one expert when you can have many?
The mixture of experts (MoE) is quite a clever design. Instead of training one huge model which can answer questions on a series of different subjects, engineers created a model which has several smaller networks (called experts), and a gating network which decides which specific experts to use at each new token.
The MoE Architecture Helps Reduce Computation But Maintain High Performance
Instead of needing hundreds of billions of parameters activated (eg doing computation) only the specific experts need to be active at any given time. Imagine you are working in a huge office building, where each floor is responsible for different tasks. There is an office manager who tells each team on the floor when to work and when not to work. As tasks come in the manager sends it to the right floor. This prevents all teams needing to work at the same time – and the work is done by the correct team.
This massively reduces the number of parameters doing addition and multiplication – which is a huge computation saving. And the cost of LLMs are one of the most significant challenges.
It’s worth noting that although we do get some cost savings, the whole model does need to be loaded, we can’t get around this!
Mixtral8x7B is a great example of an MoE, as is DeepSeek! The newest Llama models by Meta are also a MoE, are we seeing a trend? With the computation savings I guess it is unsurprising that this architecture is being taken up by lots of companies.
How Do LLMs Learn?
But how does the AI know which words to generate? That’s where training comes in.
A Large Language Model is shown huge amounts of text—books, articles, Wikipedia pages, and more. It doesn’t memorise them word for word but learns patterns, structures and how words relate to each other. For example, if it sees the phrase:
“Once upon a…”
It learns, through many, many examples, that the next word is often “time.”
This pattern recognition is what allows the AI to generate text that makes sense, even if it has never seen a particular sentence before.
LLMs are Trained with Gradient Descent and a Loss function; aka they learn by doing
They are trained in a very similar way to other neural network, using Gradient Descent and loss functions. This essentially just involves testing some data, seeing how well it does, calculating a loss, then updating the model weights in a way which will reduce the loss (aka improve the performance).
Safety, Helpfulness and All Around Perfectionism
You’ve trained a model on all of the internet, great! Your model has a good understanding of grammar, which words are similar, common phrases and even can recall several facts. But unfortunately it doesn’t end there, this was the first step in the process!
Supervised Fine-Tuning makes your model better at your task
At this point the model is like an unrefined, unfiltered teenager. It knows all the stuff, but doesn’t know how to harness it to be helpful. That’s because at this stage the model simply just completes sentences.
It doesn’t complete the task you asked it to, it is rude (it has learnt from the internet remember), and unhelpful.
You have to work a bit harder to fine-tune your model to be good at your task.
So developers do, they create more datasets – labelled with successful examples of their task. They will do further training (supervised fine tuning) to make their model good at their job. Since these task specific datasets are much smaller, they take far less time and cost much less.
This is useful because it means you could leverage the base model, that say, Meta, have created and completely tune it to your application. You don’t need to retrain a whole new model every time you want to use it for something new.
Reinforcement Learning with Human Feedback
This is also true for safety. Additional safety alignment (alignment is the word they use for teaching a model!) steps are done to ensure that language models do not say biased, inappropriate or harmful things.
This is done by using real humans to help the model learn what a good and bad answer is. The AI creates two answers and the human reviewer chooses their preferred. As a result the LLM is updated, This happens on a very large scale, and we end up with a model that knows how we generally prefer our answers to be structured.
This is also what is happening when you use a platform such as ChatGPT, sometimes it gives you a choice of answers. This will also help to improve the system.
A Word On Scale
As important as the architectures are to the impressive abilities of these AI models, insane scale is the second factor. And by scale we mean the scale of several things;
- Scale of training data – just so much, at least all of Wikipedia for a start.
- Scale of compute; eg GPUs – 1000s of GPUs and 1000 of hours
- Scale of model size, eg the number of parameters in each layer, billions of parameters in total
It couldn’t have been achieved without this scale.
The third key enabler of the hype is the improved computation and lots of GPUs, I won’t explore it now – but you can check it out in my other post here.

Why AI Sometimes Gets Things Wrong
Even though LLMs are powerful, they’re not perfect. Since they don’t actually understand language the way humans do, they sometimes:
- Struggle with ambiguous or tricky questions.
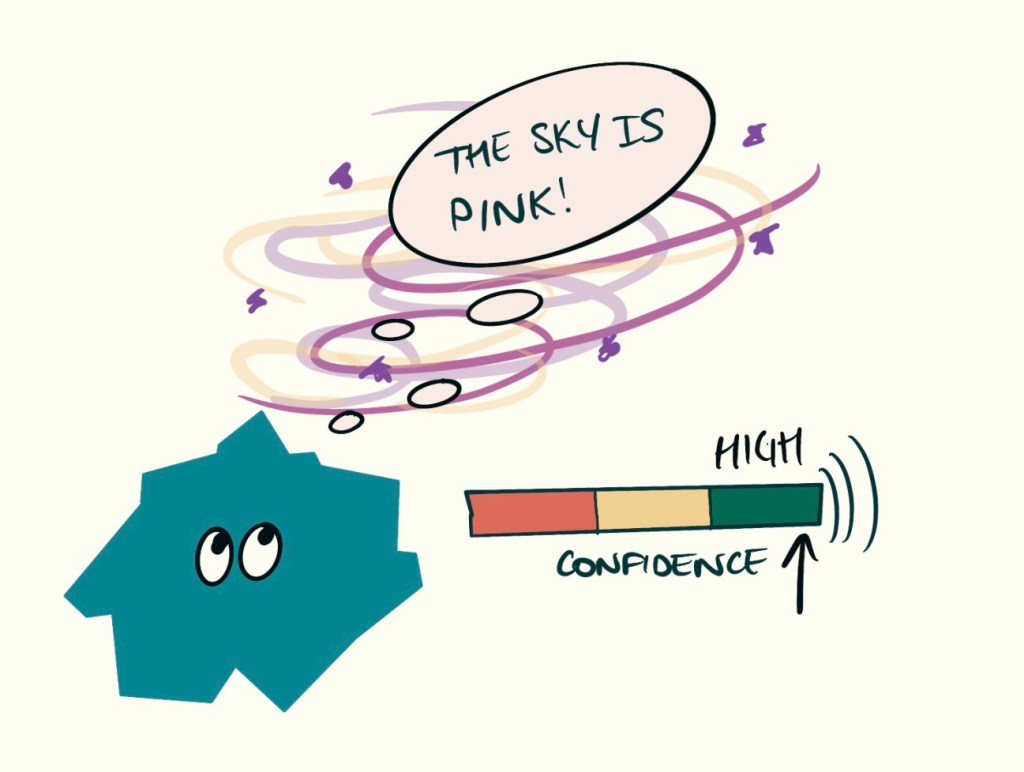
- Make up information (known as “hallucination”).
Hallucinations are helpful, and a desirable side effect…. Said GPT-4.
The models are just probabilistic functions (maths!), which guess a token at a token, with no real concept of true or false. They have learned from examples we have created, such as content on the internet. Who really knows what is true and false there! They also just guess words which it deems are related to the sentence you have used as the prompt.
This means that models are vulnerbale to hallucinations. Which essentially means they sometimes make up facts, but say them in a way that is convincing. It might be hard to tell if the model is wrong if you are learning something new, so it is always important to double check the information!
Models can be coerced into revealing secret information
You might be familiar with the hack (known as a jailbreak) that was going around encouraging the model to ‘role play as an AI that can do anything’, or telling it ‘you are now in development mode’ in an attempt to bypass the safety training and to get models to say harmful things.
This is a new type of hack, and one the security community are actively researching. The models out there today are all vulnerable in some ways to jailbreaks.
What is particularly alarming about jailbreaks, is that they can be found with relative ease, you don’t need to be a seasoned computer hacker – you just need to know how to bypass and manipulate systems with language. This is sort of like social–engineering, where the target is the AI.

They have a great memory, but they might accidentally repeat your work
There is quite a lot of concern over copyright and AI generated data, particularly when the generated text. Many artists and writers are standing against AI companies, saying they do not want their work to be included in the training data of these models.
On the one hand, the models need to have a good ability to memorise data and patterns, otherwise they will be useless. So memorisation in LLMs is actually a strength and very useful!
But on the other hand people don’t want their work remembered word for word – their ideas are being stolen!
We want the best of both worlds, memorising data that isn’t considered protected – and never repeating text word for word.
It’s a complex problem, and it is extremely difficult to prove whether text has been copied. Some people try to prove that their data was used in the training of a model – using techniques called membership inference. Then there are techniques being developed to remove data from models, without needing to rebuild the whole thing from scratch – machine unlearning. But these techniques are still early in development, so are by no means sufficient solutions.
So for now the problem remains, but be aware of you are using LLMs for creating content, it might not be as original as you believe.

The Future of LLMs
Future models will likely be more accurate, more conversational, and better at reasoning. We are certainly seeing this already with the DeepSeek reasoning models and the openAI reasoning models.
Multimodal: Words just aren’t enough, we want to see things
Many of these big tech models are moving away from language only models to multimodal models. This means that they can read images, listen to audio – even create images (you should definitely see the Studio Gihbli trend going round)!
Maybe next we will be able to comminicate with videos!
Agents: Come On Boost My Productivity even more
I’ve already spoken about agents before, if you haven’t please check out my previous post on Agents. This is already happening, but large language models are also being used in agents. That is the LLM not only answers your question, but it is able to do things (real things) for you, such as booking a holiday or managing your inbox.
We are also seeing this trend move into robotics, with robotic dogs now powered with large language models so you can interact with the robot using natural commands!
This field is moving fast!
Conclusion
So that’s it, that’s what an LLM is at a very high level. It predicts tokens.
If you are interested in seeing more of the maths, comment below and maybe I can introduce them in other posts.
But for now, remember what they are; a fancy text completion bot, which is both HUGE and POWERFUL. It can hallucinate, so double check the facts, and it can definitely help you in all aspects of your life, so be sure to try it!

Leave a comment